SoC 設計與應用技術領導廠商Socionext Inc.宣佈,聯合大阪大學資料能力科學研究所,長原教授(Hajime Nagahara)研究小組,共同開發新型深度學習演算法,該演算法無需製作龐大的資料集,只需通過融合多個模型便可在極度弱光線條件下進行精準檢測物體及影像識別。Socionext笹川幸宏先生和大阪大學長原教授在8月23日至28日(英國夏令時間)舉辦的歐洲電腦視覺國際會議(ECCV 2020)上報告這一研究成果。https://eccv2020.eu/
近年來儘管電腦視覺技術取得了飛速發展,但在低照度環境下車載攝影機、安防系統等獲取的影像品質仍不理想,影像辨識性能較差。不斷提升低照度環境下影像識別性能,依舊是目前電腦視覺技術面臨的主要課題之一。CVPR2018中一篇名為《Learning to See in the Dark》[1]的論文曾介紹過利用影像傳感器的RAW影像資料的深度學習演算法,但這種演算法需要製作超過200,000張圖像和150多萬個批註[2]的資料集才能進行端到端學習,既費時又費錢,難以實現商業化落地(如下圖1)。
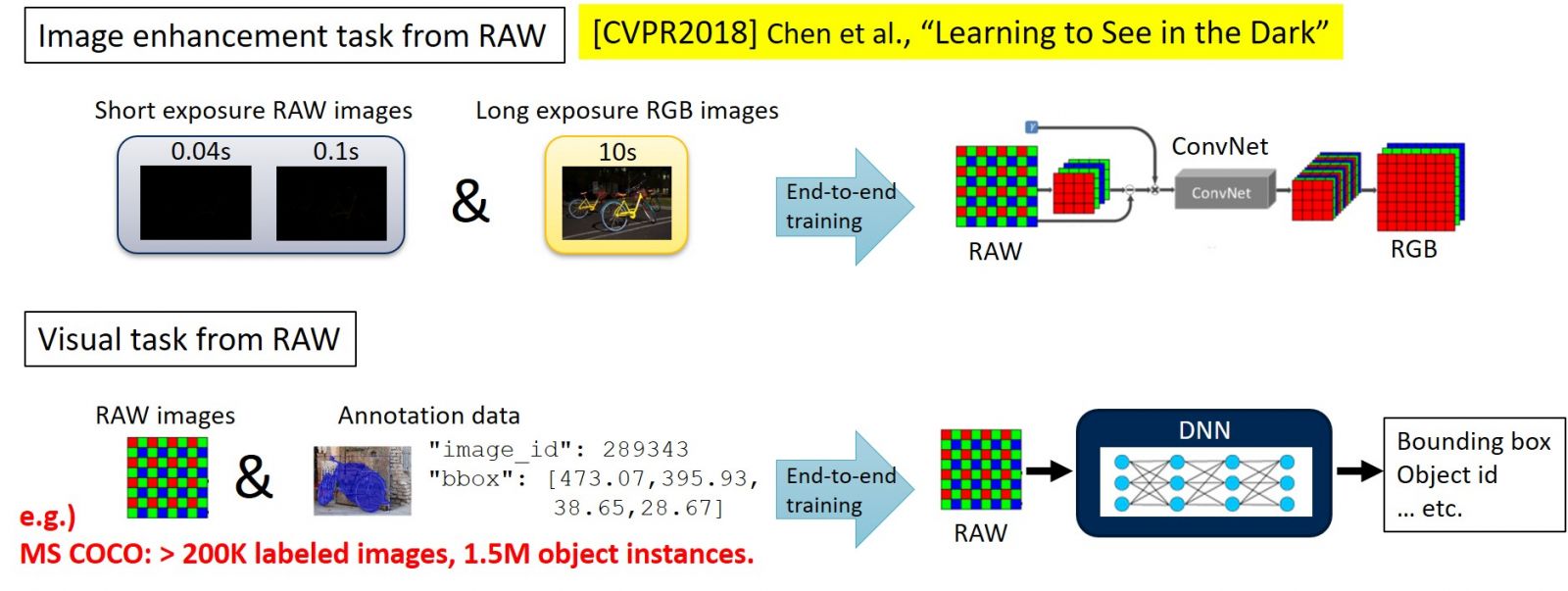
圖1:《Learning to See in the Dark》及RAW 影像識別課題
為解決上述課題,Socionext與大阪大學聯合研究團隊通過遷移學習(Transfer Learning)和知識蒸餾(Knowledge Distillation)等機器學習方法,提出採用領域自我調整(Domain Adaptation)的學習方法,即利用現有資料集來提升目標域模型的性能,具體內容如下(如圖2):
(1)使用現有資料集構建推論模型;
(2)通過遷移學習從上述推論模型中提取知識;
(3)利用Glue layer合併模型;
(4)通過知識蒸餾建立並生成模型。
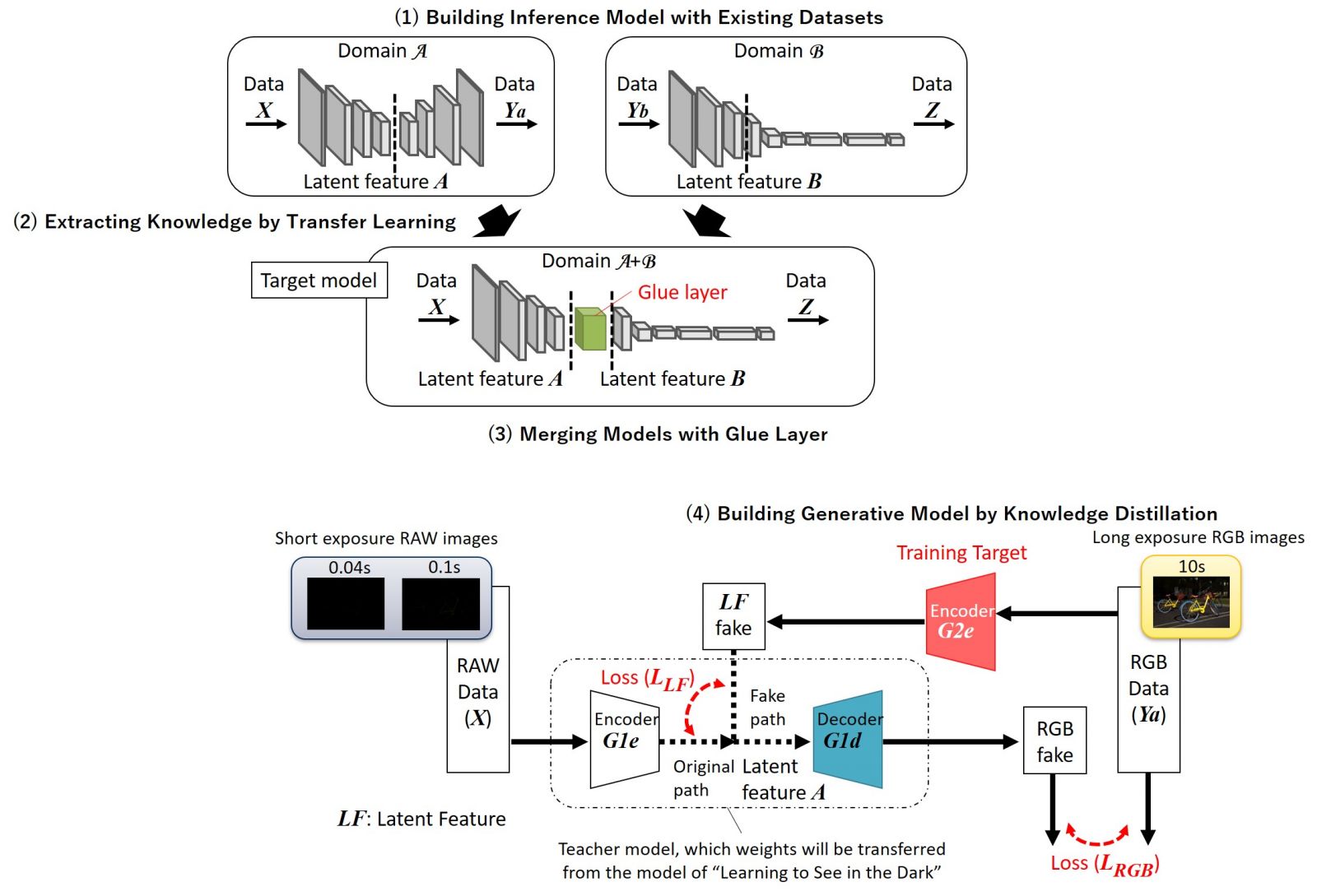 圖2:本次開發的領域適應方法(Domain Adaptation Method)
圖2:本次開發的領域適應方法(Domain Adaptation Method)
此外,結合領域自我調整方法和物體檢測YOLO模型[3],並利用在極端弱光條件下拍攝的RAW影像還可構建 “YOLO in the Dark” 檢測模型。YOLO in the Dark模型可僅通過現有資料集實現對RAW影像的物件檢測模型的學習。針對那些通過使用現有YOLO模型,校正圖像亮度後仍無法檢測到圖像的(如下圖a),則可以通過直接識別RAW影像確認到物體被正常檢測(如下圖b)。同時測試結果發現,YOLO in the Dark模型識別處理時所需的處理量約為常規模型組合(如下圖c)的一半左右。

圖3:《YOLO in the Dark》效果圖
本次利用領域自我調整法所開發的“直接識別RAW影像”可不僅應用於極端黑暗條件下的物體檢測,還可應用於車載攝影機、安防系統和工業等多個領域。未來,Socionext還計畫將該技術整合到Socionext自主研發的影像處理器(ISP)中開發下一代SoC,並基於此類SoC的開發全新攝像系統,進一步提升公司產品性能,助力產業再升級。
歐洲電腦視覺國際會議(ECCV 2020)
日期:8月23~28日(英國夏令時間)
地點:線上會議
演講主題:YOLO in the Dark - Domain Adaptation Method for Merging Multiple Models -
演講人:Socionext Inc. 笹川幸宏先生
大阪大學 長原教授
註釋:
[1] “Learning to See in the Dark” : CVPR2018, Chen et al.
[2] MS COCO dataset as an example (https://cocodataset.org/)
[3] YOLO (You Only Look Once): One of the deep learning object detection methods